01基本概念
答疑学习Q群:1032334293 微信:xxdlovo
RPA知识库: https://4a.al/rpa
题目内容
影刀rpa初级证书-01基本概念-源码
题目:
题1
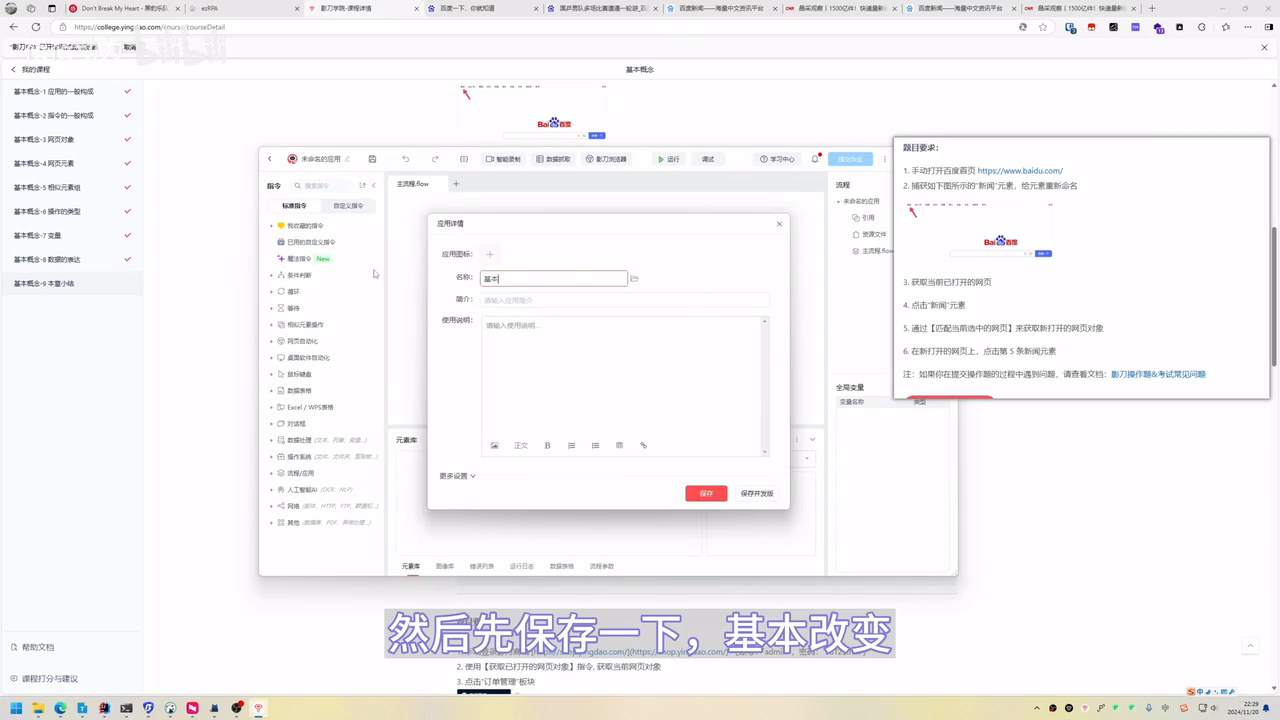
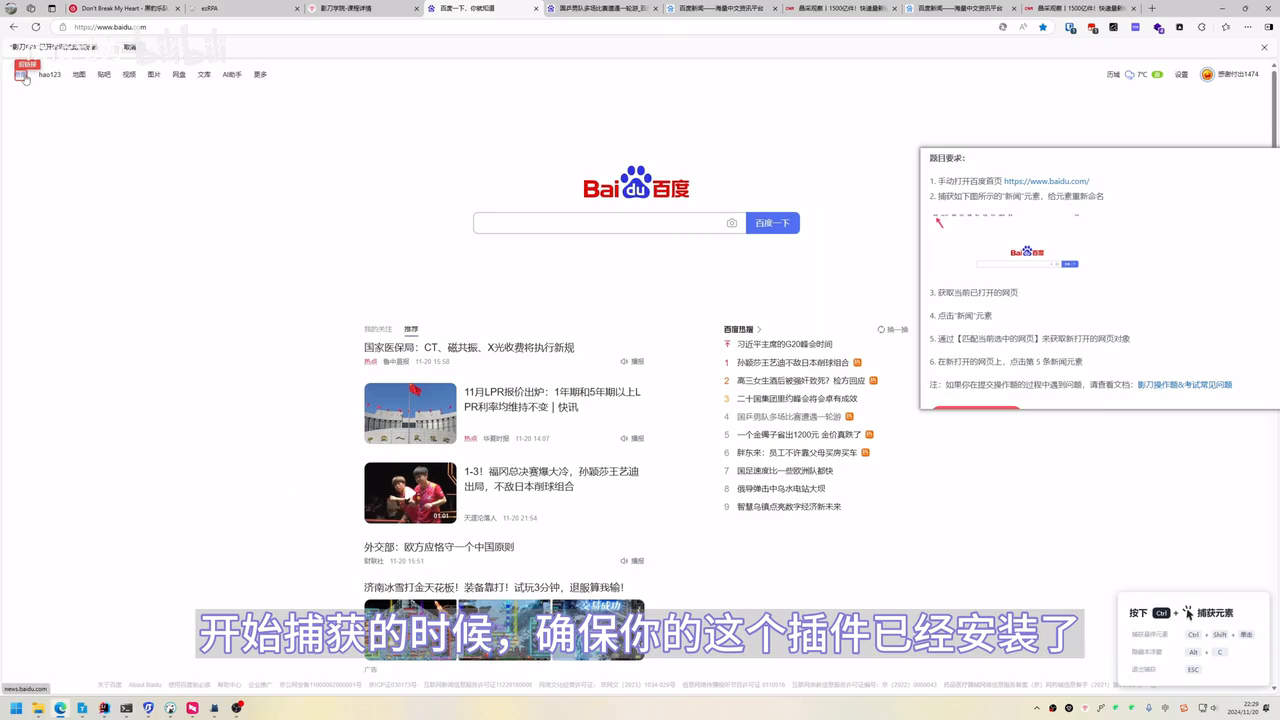
- 手动打开百度首页 https://www.baidu.com/
- 捕获如下图所示的“新闻”元素,给元素重新命名

- 获取当前已打开的网页
- 点击“新闻”元素
- 通过【匹配当前选中的网页】来获取新打开的网页对象
- 在新打开的网页上,点击第 5 条新闻元素'
题2
1.手动登录影刀商城 https://shop.yingdao.com (账号:admin ,密码:58T2$!hm)
2. 使用【获取已打开的网页对象】指令, 获取当前网页对象
3. 点击“订单管理”板块
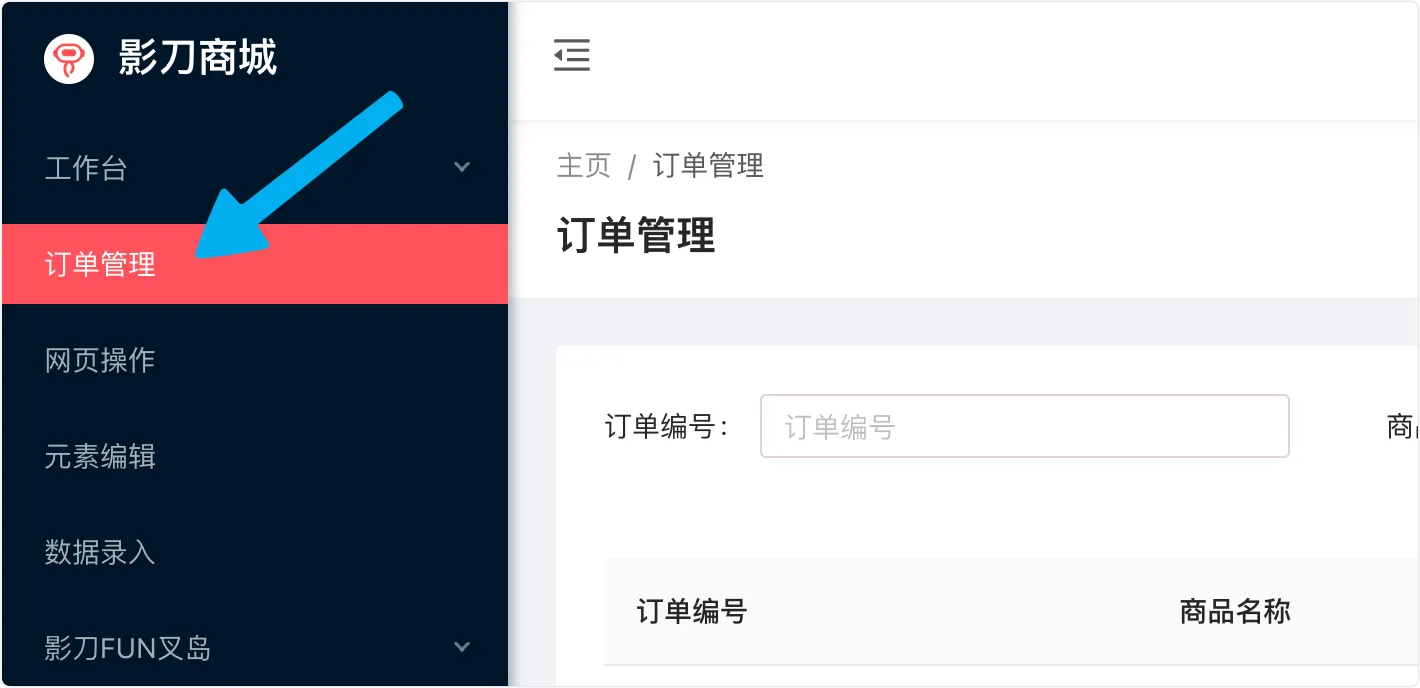
4. 使用【循环相似元素(web)】指令依次点击第 1 页订单列表中的“确认发货”并点击“确定”'
相关链接:
资源打包: https://pan.quark.cn/s/53cd836ccf0c
B站视频: https://www.bilibili.com/video/BV1gcTkzMEaN/
选择题题库: ima知识库
源码截图:


基本概念操作题步骤解析
以下内容由AI整理并生成, 仅供参考
课程介绍与准备工作
- 进入影刀RPA初级教程的「目标一-基本概念」章节,定位至最后一小节的操作题部分
- 准备贴图软件截取两道操作题界面备用
- 登录影刀客户端创建答题环境,建议新建流程命名为「操作题1」
 第一题:网页元素捕获与索引定位
第一题:网页元素捕获与索引定位
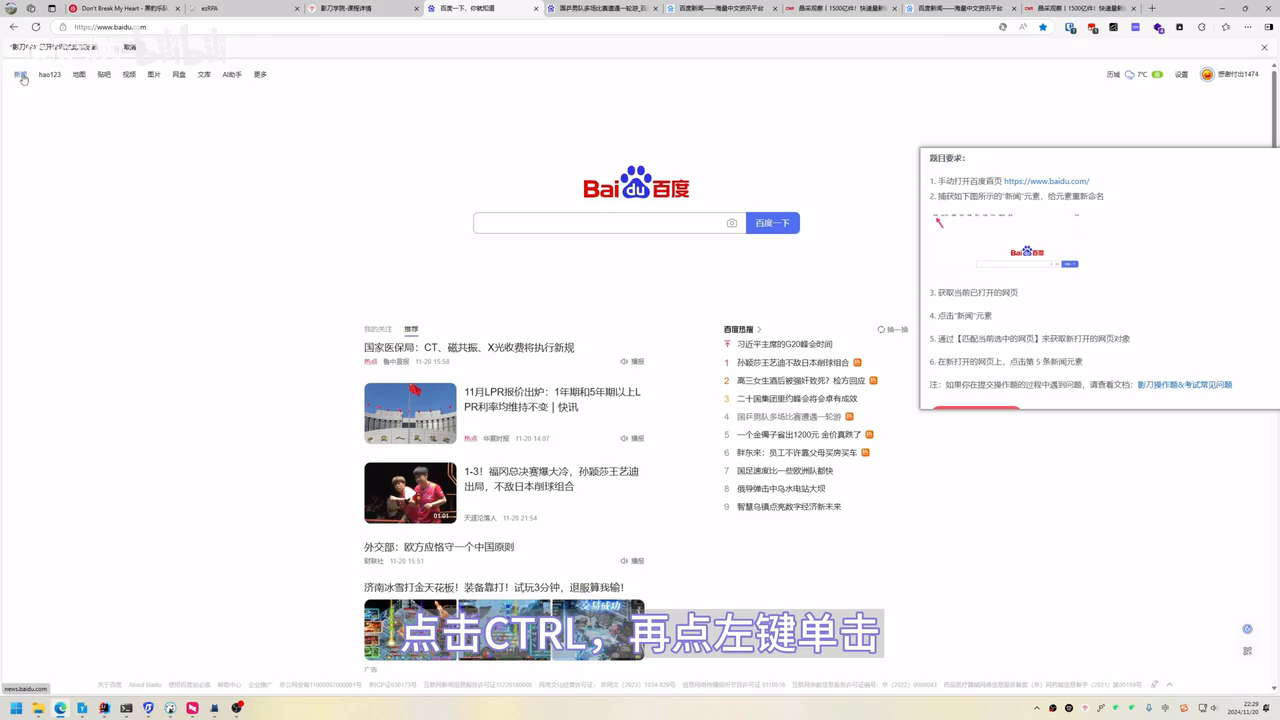
- 启用元素捕获插件,悬浮定位目标元素后使用Ctrl+左键单击捕获
- 解析HTML结构:
- UL表示无序列表容器
- LI对应列表项元素
- strong标签定义加粗文本(可忽略样式处理)
- 索引定位规则: | 显示序号 | 索引值 |
| -------- | ------ |
| 第1条 | 0 |
| 第5条 | 4 | - 元素属性配置:
<li class="news-item" index="v4">...</li>
 网页自动化流程搭建
网页自动化流程搭建
- 创建「获取网页对象」组件:
- 浏览器类型需与实际环境一致
- URL匹配模式设置为「包含baidu.com」
- 操作链配置:
- 首次获取网页对象 → 点击新闻导航 → 重新获取网页对象(解决页面跳转问题)
- 调试技巧:
- 使用分步调试定位元素查找失败问题
- 通过标签页管理确保操作上下文正确
 第二题:循环操作与动态元素处理
第二题:循环操作与动态元素处理
- 登录系统后进入订单管理模块
- 元素捕获策略:
- 主菜单项「订单管理」
- 操作按钮「确认发货」
- 弹窗控件「确定」
- 相似元素批量处理:
elements = get_similar_elements('确认发货') for element in elements: element.click() confirm_dialog.click() - 动态元素处理要点:
- 使用XPath相对路径定位
- 设置合理的元素匹配阈值
- 添加失败重试机制
 常见问题解决方案
常见问题解决方案
- 元素定位失效处理:
- 检查浏览器缩放比例(需保持100%)
- 验证页面DOM结构更新情况
- 添加显式等待机制
- 跨页面操作规范:
- 每次页面跳转后需重新获取网页对象
- 使用「切换到最新标签页」命令
- 执行速度优化:
- 合理设置操作间隔时间
- 启用无头模式进行批量测试
 作业提交与验证
作业提交与验证
- 流程保存规范:
- 按「功能模块_日期」格式命名
- 添加必要的流程注释
- 提交前检查:
- 运行日志完整性验证
- 截图关键步骤执行结果
- 参考答案对比:
- 重点核对元素定位策略
- 验证循环结构的有效性
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 码上RPA

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果